New $5M NSF Award Will Power PegasusAI, an AI-Driven Workflow System to Accelerate Science from the Edge to the Cloud and High-Performance Computing
A collaborative team from the University of Southern California’s Information Sciences Institute (ISI), the University of Tennessee, the University of Massachusetts Amherst, and the University of North Carolina at Chapel Hill has received a $5 million award from the U.S. National Science Foundation (Award No. 2513101) to develop PegasusAI. Building on the proven Pegasus Workflow Management System, PegasusAI will integrate advanced AI to automate resource provisioning, predict performance, detect anomalies, and guide scientists through human-in-the-loop adaptation. This next-generation framework will enable researchers to seamlessly execute and manage complex workflows across the entire computing continuum—from edge devices to exascale systems.
The project, titled “CSSI: Frameworks: Applying Artificial Intelligence Advances to the Next Generation of Workflow Management on Modern Cyberinfrastructure,” will create PegasusAI, a modular, intelligent extension of the widely adopted Pegasus workflow management system. PegasusAI will harness recent advances in AI to bring greater automation, adaptability, and insight to data-intensive scientific workflows that operate across high-performance computing (HPC), cloud, and edge systems.
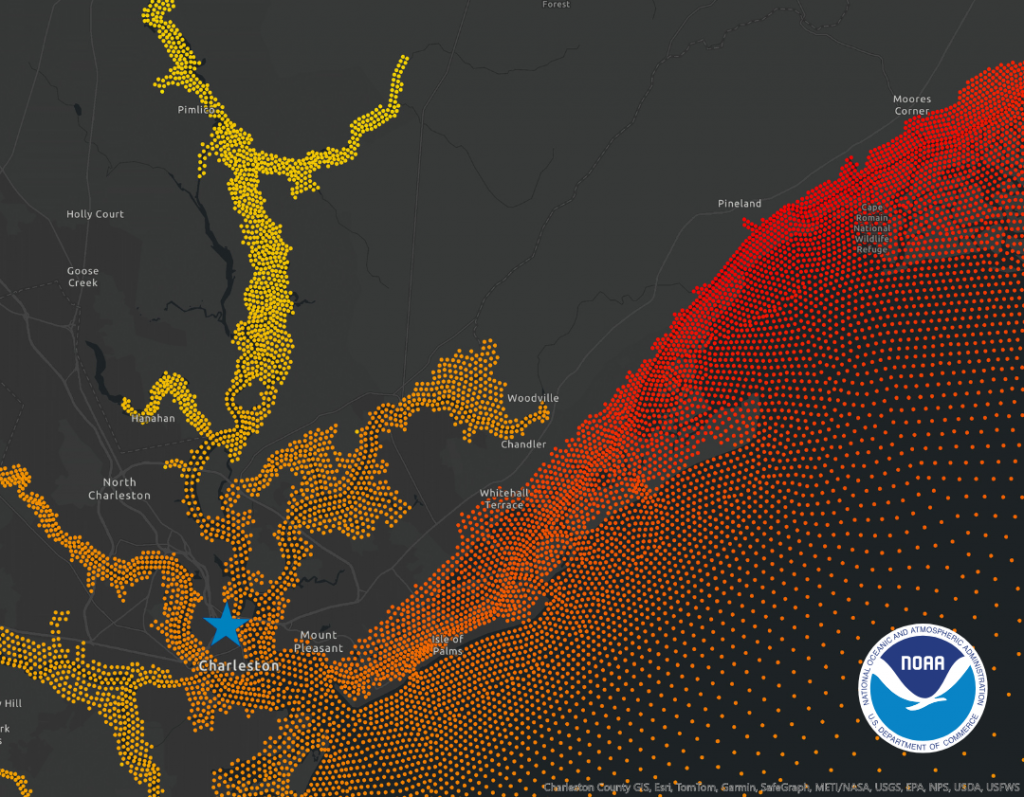
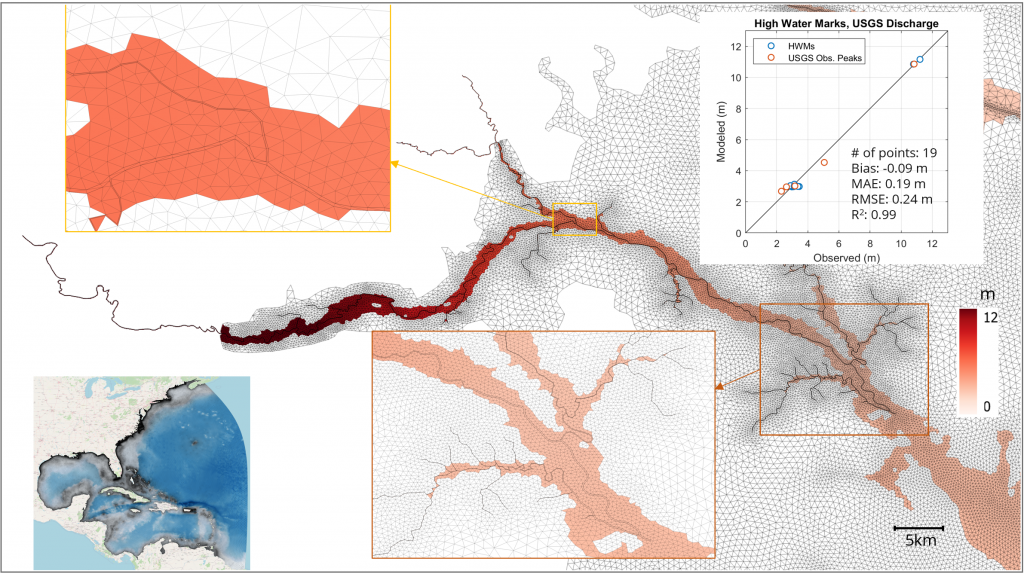
By enhancing the reliability and usability of distributed systems, PegasusAI will help scientists tackle some of today’s most pressing challenges—from modeling black holes and predicting hurricanes, to advancing cancer research and monitoring space debris. The system will also contribute foundational technologies to the broader NSF cyberinfrastructure ecosystem, enabling researchers across the U.S. to leverage NSF-supported computing platforms and services with greater efficiency and ease.
The project brings together experts in workflow systems, AI, performance modeling, real-time analytics, distributed computing, and cyberinfrastructure across the four institutions:
- Ewa Deelman, Ph.D., University of Southern California (Lead PI)
- Anirban Mandal, Ph.D., University of North Carolina at Chapel Hill
- Sai Swaminathan, Ph.D., University of Tennessee
- Michela Taufer, Ph.D., University of Tennessee
- Michael Zink, Ph.D., University of Massachusetts Amherst
“PegasusAI will bring unprecedented automation, adaptability, and resilience to data-intensive scientific workflows. By embedding AI directly into resource provisioning, performance prediction, anomaly detection, and user interfaces, we aim to create a system that is both powerful and easy to use—capable of meeting the needs of today’s most demanding science while lowering barriers for new users,” said Ewa Deelman, Ph.D., Principal Investigator of PegasusAI and Research Professor at the University of Southern California and ISI Research Director.
“As scientific workflows grow more complex and span across cloud, HPC, and edge systems, there is a critical need to move from static execution to intelligent, adaptive workflow management,” said Michela Taufer, Dongarra Professor at the University of Tennessee. “PegasusAI will apply AI to optimize resource usage, predict performance, detect anomalies, and guide users through human-in-the-loop adaptation.”
“We want to make building and managing scientific workflows 100 times easier,” said Sai Swaminathan, Assistant Professor at the University of Tennessee. “Our work focuses on designing intelligent, human-centered interfaces that help researchers—regardless of their scientific background—compose, adapt, and steer complex workflows in a more user-friendly manner. We’re also exploring how PegasusAI can better understand human intent and decision-making in real-time, so that scientific discovery becomes more interactive, adaptive, and inclusive.”
“In conjunction with the development of an AI-driven resource ecosystem, PegasusAI seeks to provide training for domain scientists in the design and implementation of scientific workflows,” said Michael Zink, Paros Professor of Geophysical Sensing Systems at the University of Massachusetts Amherst. “This training represents a critical component of the project, aimed at enabling users with varying levels of technological proficiency to effectively utilize next-generation workflow systems. “
“With the resource ecosystem for executing scientific workflows getting increasingly complex and spanning the edge-to-core continuum, provisioning and automatically tailoring resources for workflows is becoming a significant challenge that scientists have to navigate,” said Anirban Mandal, Director for Network Research and Infrastructure at RENCI, UNC Chapel Hill.
This award is part of NSF’s Cyberinfrastructure for Sustained Scientific Innovation (CSSI) program, which supports the development of sustainable and extensible software frameworks that serve scientific communities and support future innovation.
To learn more, visit the NSF award page: https://www.nsf.gov/awardsearch/showAward?AWD_ID=2513101